一个简单的爬虫代码,爬取的有的会有一点偏差的,我也是新手,勿喷
-----------------------------------------------------------------------------------------------
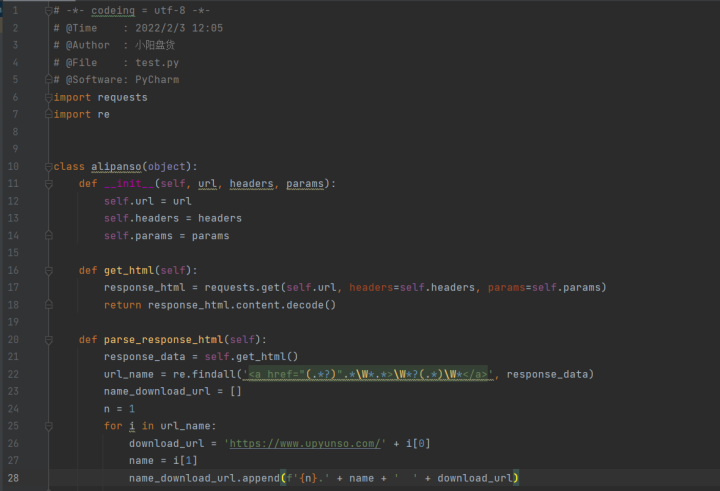
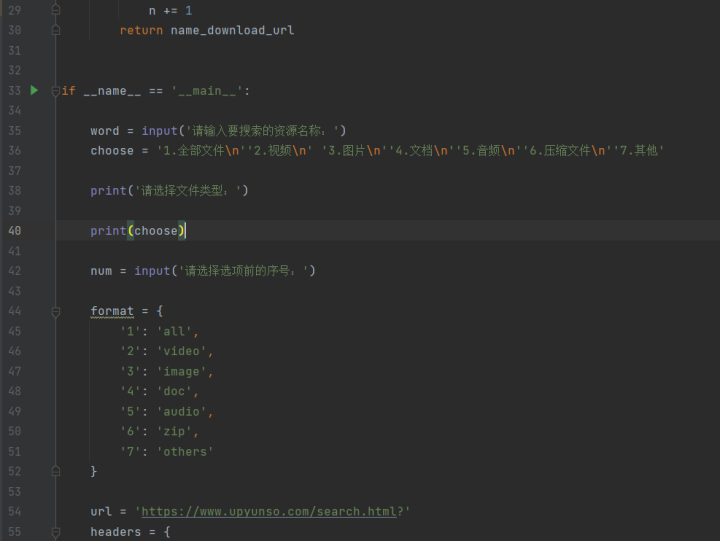
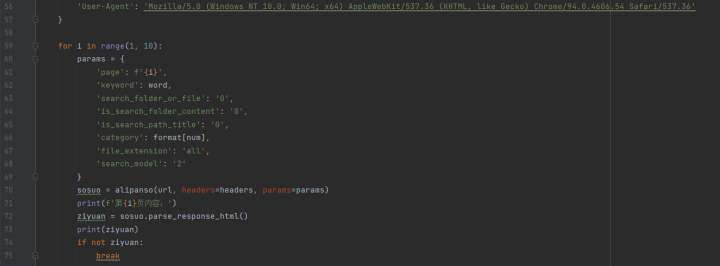
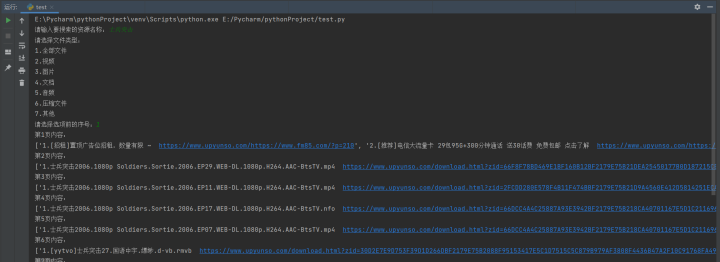
# -*- codeing = utf-8 -*-# @Time : 2022/2/3 12:05# @Author : 小阳盘货# @File : test.py# @Software: PyCharmimport requestsimport reclass alipanso(object): def __init__(self, url, headers, params): self.url = url self.headers = headers self.params = params def get_html(self): response_html = requests.get(self.url, headers=self.headers, params=self.params) return response_html.content.decode() def parse_response_html(self): response_data = self.get_html() url_name = re.findall('<a href="(.*?)".*\W*.*>\W*?(.*)\W*</a>', response_data) name_download_url = [] n = 1 for i in url_name: download_url = 'https://www.upyunso.com/' + i[0] name = i[1] name_download_url.append(f'{n}.' + name + ' ' + download_url) n += 1 return name_download_urlif __name__ == '__main__': word = input('请输入要搜索的资源名称:') choose = '1.全部文件\n''2.视频\n' '3.图片\n''4.文档\n''5.音频\n''6.压缩文件\n''7.其他' print('请选择文件类型:') print(choose) num = input('请选择选项前的序号:') format = { '1': 'all', '2': 'video', '3': 'image', '4': 'doc', '5': 'audio', '6': 'zip', '7': 'others' } url = 'https://www.upyunso.com/search.html?' headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.54 Safari/537.36' } for i in range(1, 10): params = { 'page': f'{i}', 'keyword': word, 'search_folder_or_file': '0', 'is_search_folder_content': '0', 'is_search_path_title': '0', 'category': format[num], 'file_extension': 'all', 'search_model': '2' } sosuo = alipanso(url, headers=headers, params=params) print(f'第{i}页内容:') ziyuan = sosuo.parse_response_html() print(ziyuan) if not ziyuan: break
 电影/剧集
电影/剧集 动漫
动漫 音频
音频 图片
图片 游戏/软件
游戏/软件 学习
学习 求资源
求资源


 主页
主页

